Yayın tarihi: 27 Ocak 2026
Bu yazı en son 5 Mart 2026 tarihinde güncellenmiştir.
Bu rehberde YOLO ile custom object detection – kendi veri setinizle nesne tespiti yapılacaktır.
Önemli not: Hata aldığınız noktaları lütfen yorumlarda belirtin. Bunların çözümlerine karşılaşılan hatalar kısmında yer vermeye çalışacağım. Bunun yanı sıra yapay zeka araçları hata çözme konusunda son derece yetenekli
Yapılacaklar sırası
- Donanım ve yazılım gereksinimleri
- Gerekli yazılımların kurulması
- Anaconda/Miniconda
- VS Code
- Veri setinin hazırlanması
- Veri toplama
- Cihaz
- Webcamle veri toplama
- Telefonla veri toplama
- Dosyaları PC’ye aktarma
- Yöntem
- Fotoğraf ile veri toplama
- Video ile veri toplama
- Videonun parçalara ayrılması
- Veri etiketleme
- Yolo .txt veri formatı
- Etiketleme aracı
- Manuel ve otomatik etiketleme
- Klasör yapısının hazırlanması
- data.yaml dosyasının hazırlanması
- Cihaz
- Veri toplama
- Eğitim
- Sonuçların değerlendirilmesi
- Tahmin
Donanım – yazılım gereksinimleri
Bu rehber bilgisayarınızın Nvidia GPU’ya sahip olduğu ve Windows işletim sistemini kullandığınız varsayılarak hazırlanmıştır.
Gerekli yazılımların kurulması
- Anaconda/Miniconda veri bilimi alanında en sık kullanılan araçlardan ikisidir. Kütüphane çakışmalarını önlemek, sistemden izole ortamlar oluşturmak için kullanılır.
- VS Code en sık kullanılan kodlama araçlarından biridir. Bu rehber boyunca VS Code kullanılacaktır.
Anaconda/Miniconda kurulumu
Anaconda yanında bir çok kütüphane ile birlikte gelen büyük bir dağıtımken Miniconda bunun olabildiğince fazlalıklardan arındırılmış halidir. Bu rehberde Miniconda kullanılacaktır.
Anaconda/Miniconda indirme bağlantısı: https://www.anaconda.com/download/success
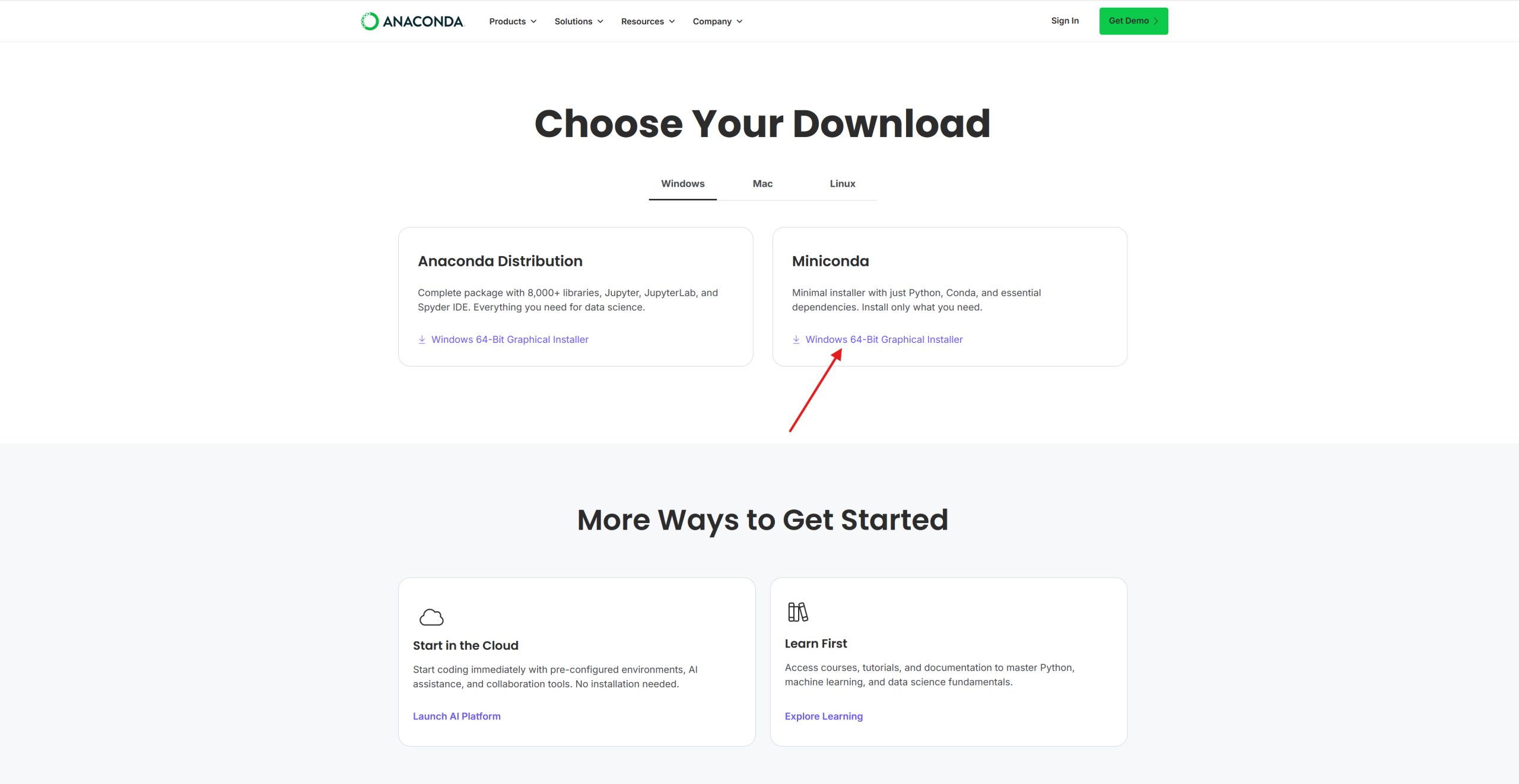
Bu sayfadan Miniconda’yı indiriyoruz.
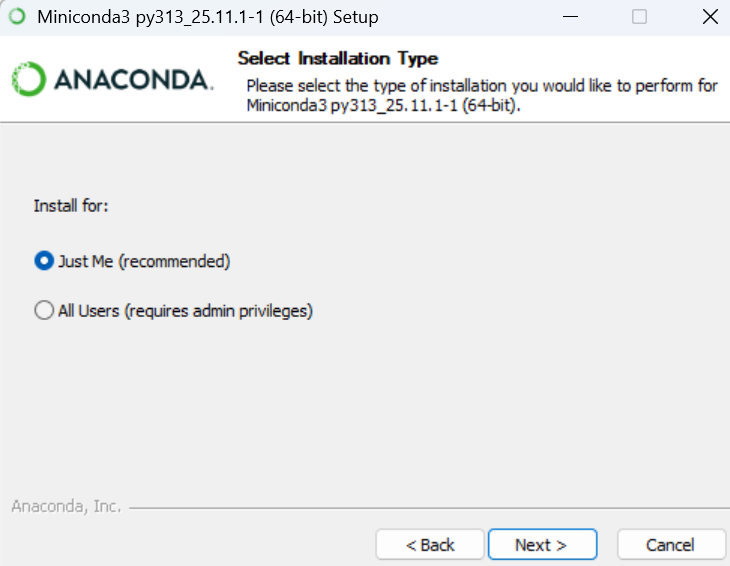
Just Me seçeneği ile sadece hali hazırda aktif olan kullanıcı için kurulumu gerçekleştiriyoruz.
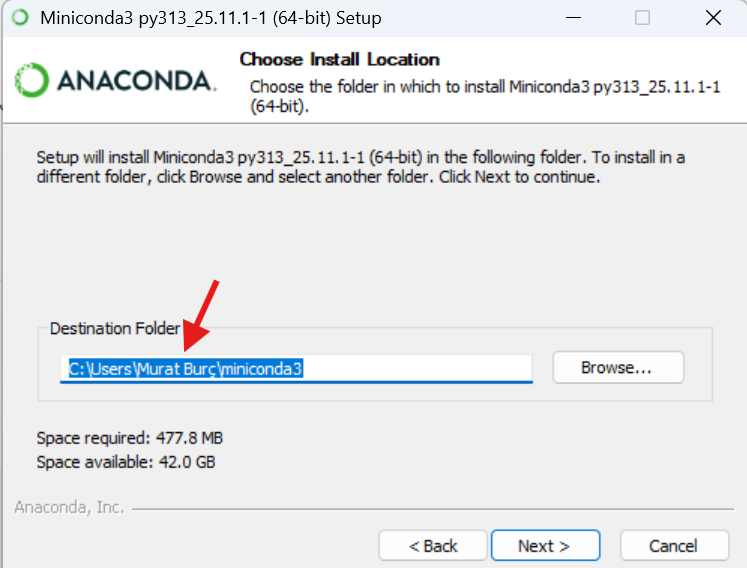
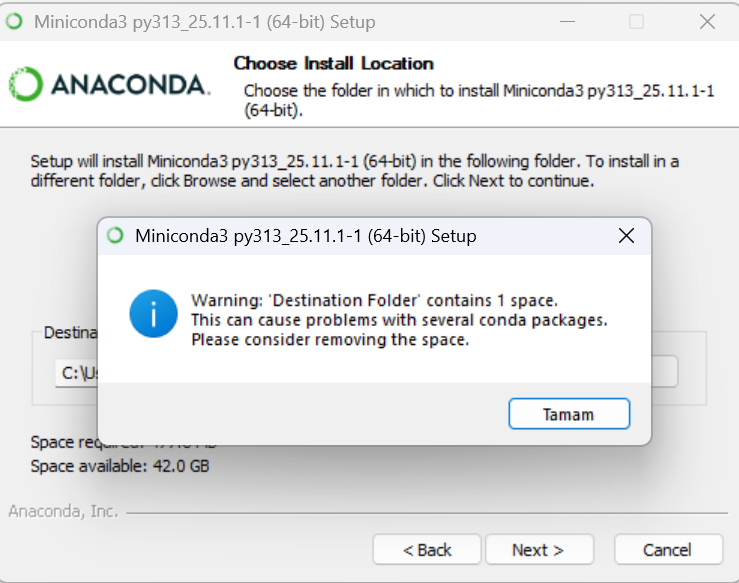
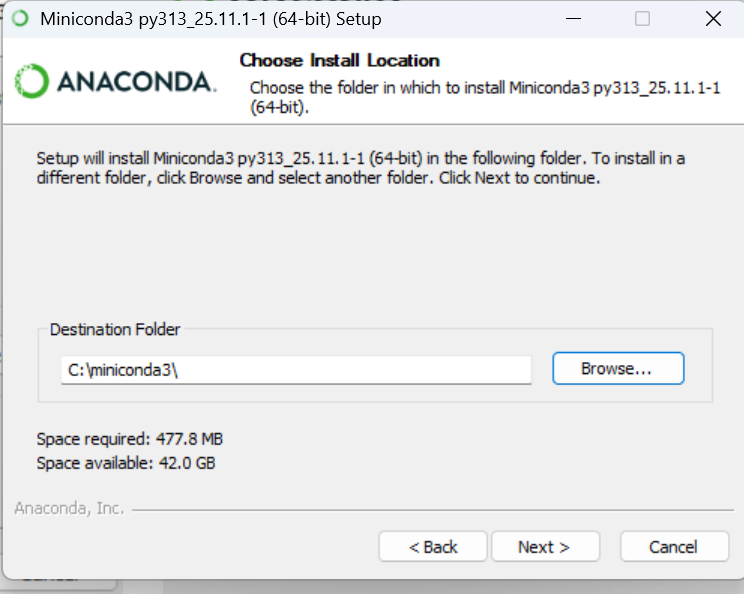
Kurulum yolunda boşluk olduğu için uyarı verecek. Kurulum yolunu olabildiğince sade tutmaya çalışın bu kurulum yolu önem arz etmekte.
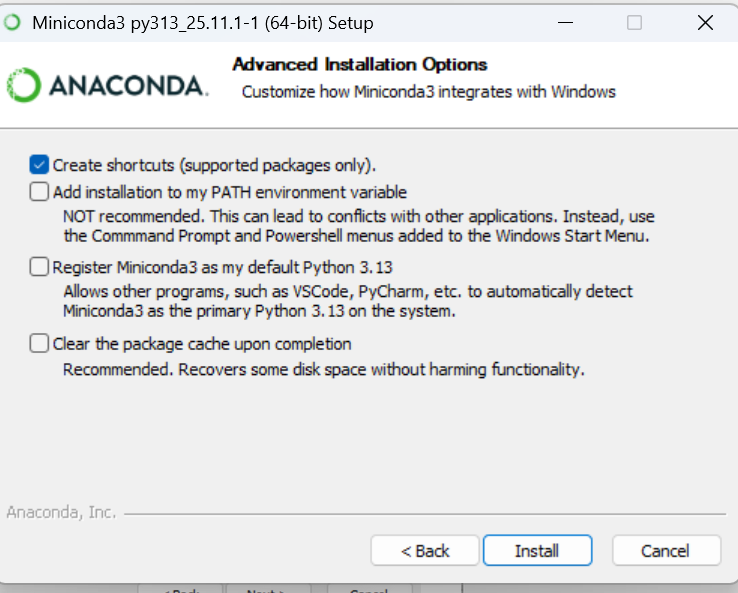
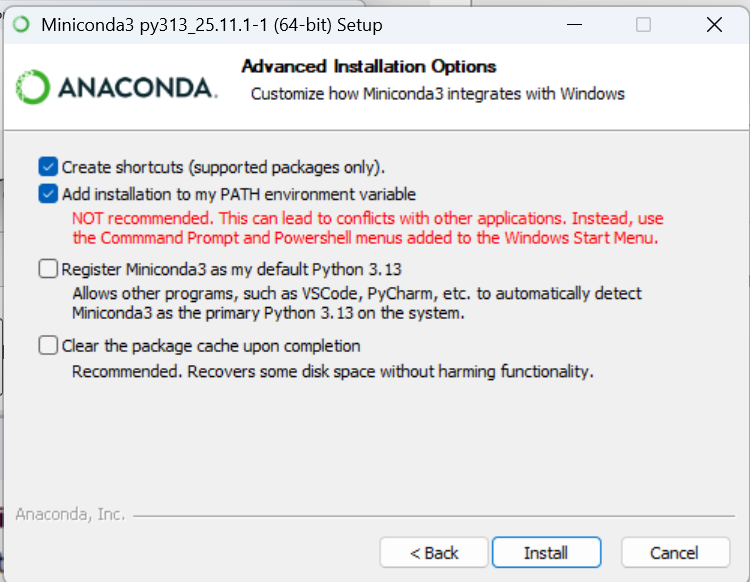
Not recommended şeklinde ifade edilen ikinci seçenek anaconda yollarını PATH’e (ortam değişkenlerine) ekler. CMD ve PowerShell’de conda komutlarını çalıştırabilmek için bu seçeneği seçmemiz gerekiyor. Ayrıca bunun da yeterli gelmediği durumlar oluyor. Aldığım hataları ve çözümleri rehberin ileri aşamalarında anlatacağım.
Not: Install dedikten sonra kurulum safhası nispeten uzun sürebilir, sabırlı olun.
VS Code kurulumu
VS Code indirme bağlantısı: https://code.visualstudio.com/download
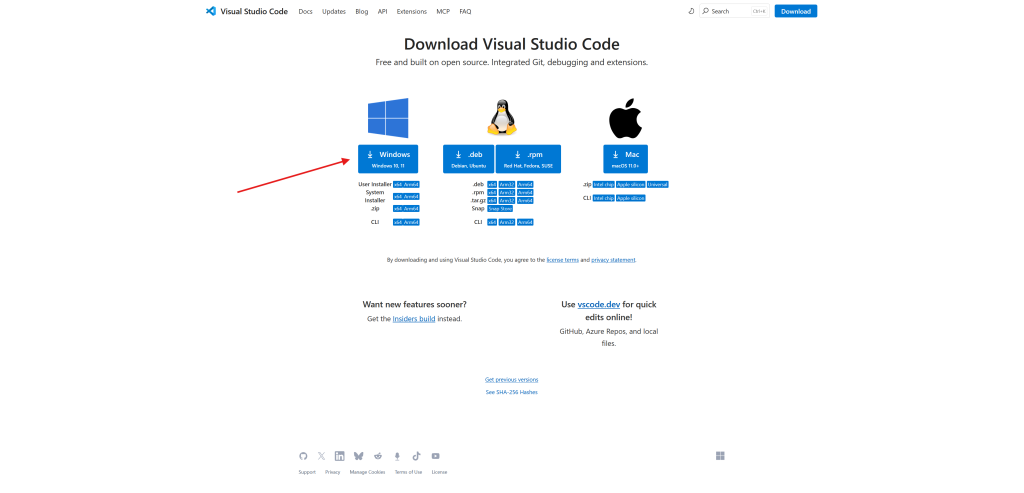
Bu sayfadan VS Code’u indiriyoruz ve next – next diyerek kuruyoruz. Ekstra bir adım gerekli değil.
VS Code karşımıza böyle bir ekranla geliyor. Burada yapmamız gereken bazı ön işlemler mevcut.
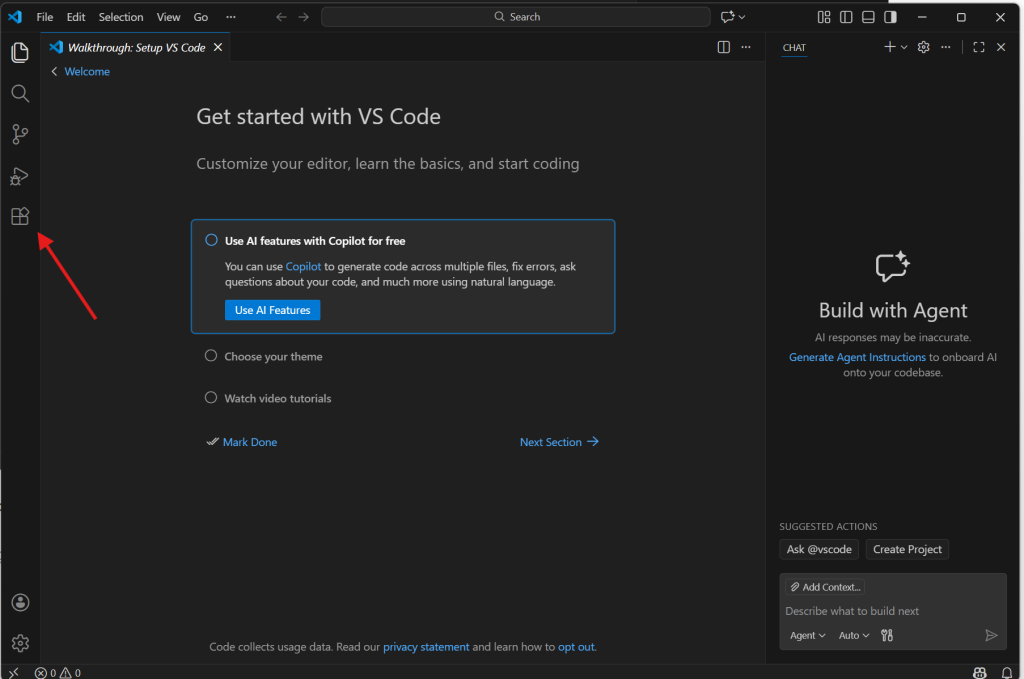
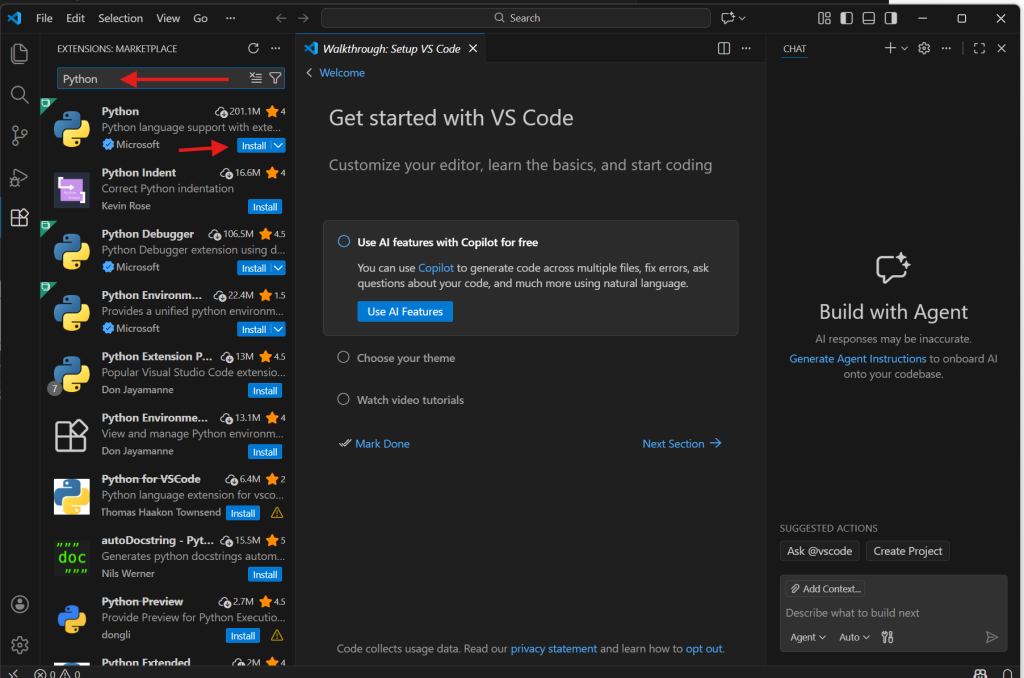
Oklarla gösterilen kısımdan extensions kısmına girin. Arama kısmından Python şeklinde arama yapın ve ilk çıkan, Microsoft tarafından dağıtılan, Python’u yükleyin. Gerekli paketler beraberinde otomatik olarak yüklenecektir.
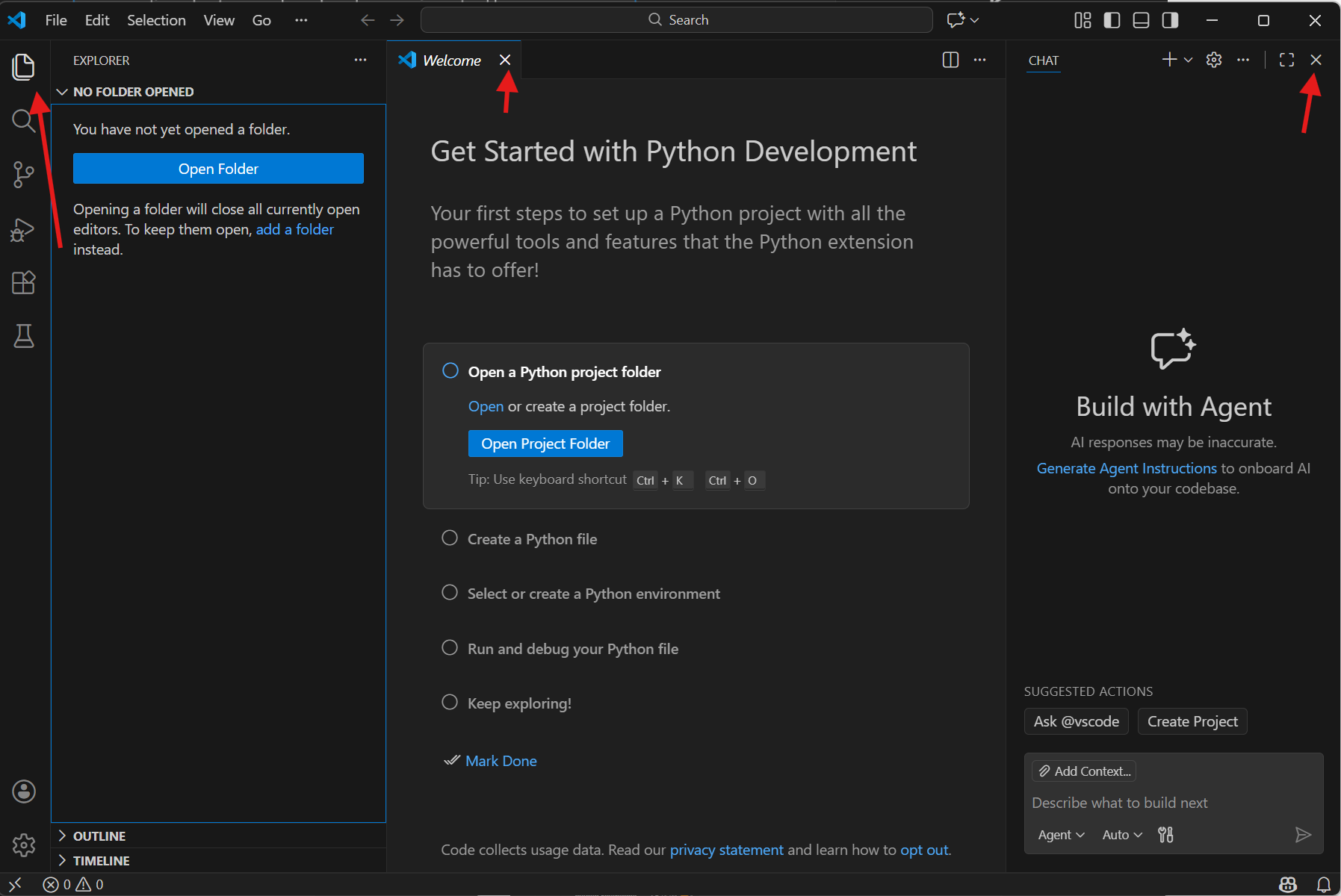
İlgili kısımlardan önce explorer kısmına gelin. Ardından ekrandaki gereksiz kısımları oklarla gösterilen tuşlardan kapatın.
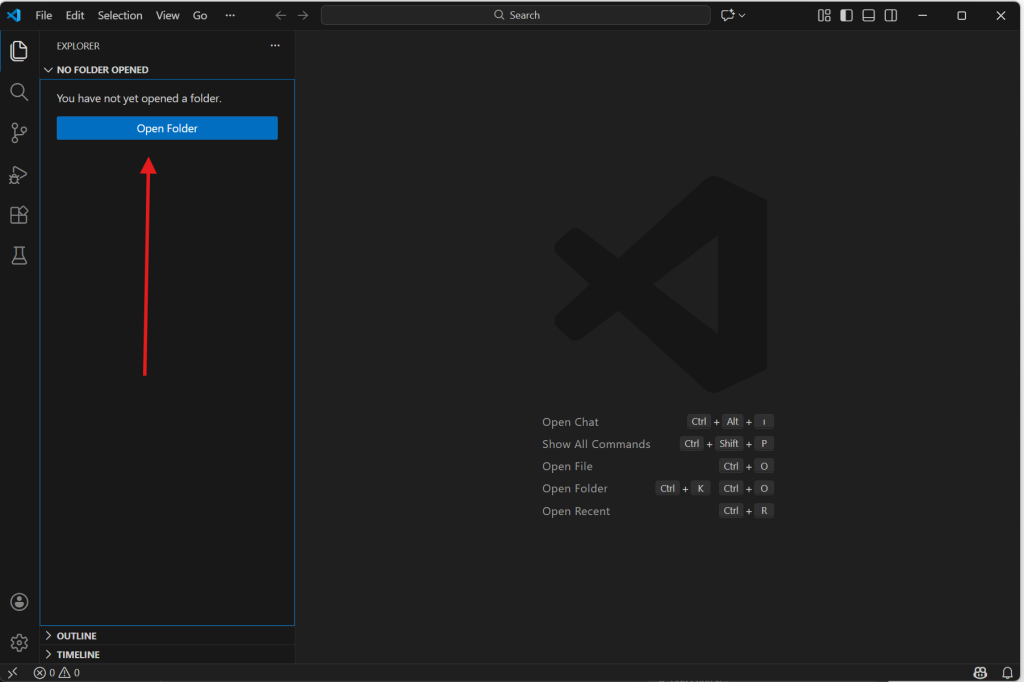
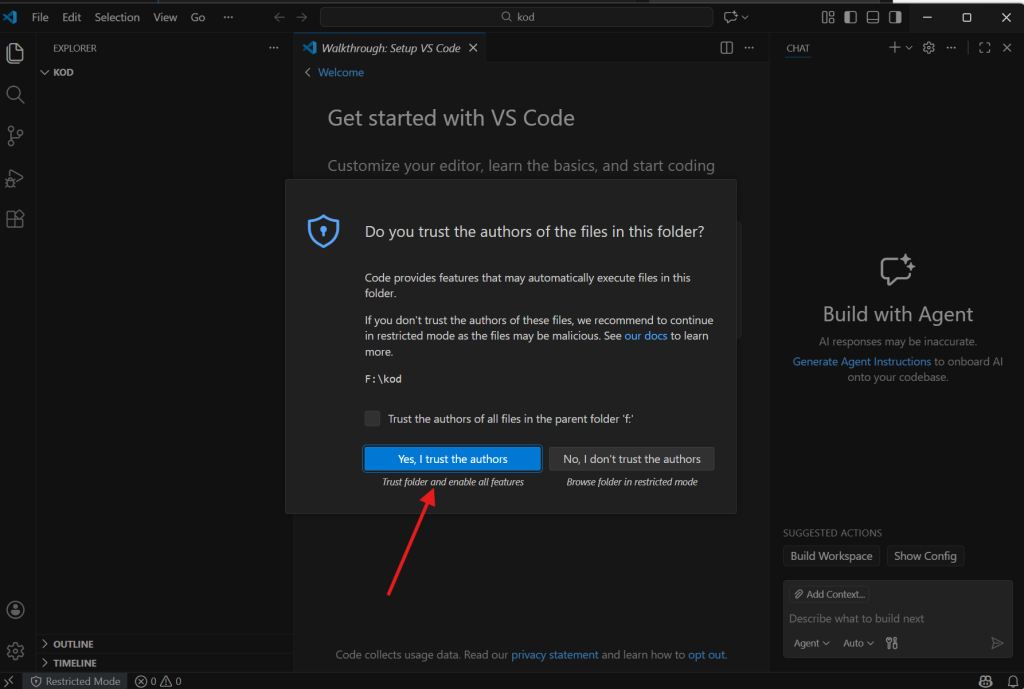
Open Folder butonuyla uygun bir konumda yeni bir klasör açın ve seçin. Karşınıza gelen güveniyor musunuz sorusuna güveniyorum cevabını verin. Burada da sadelik amacıyla F:\kod yolunu belirledim. Bu klasörde dosyalarımızı ve kodlarımızı tutacağız.
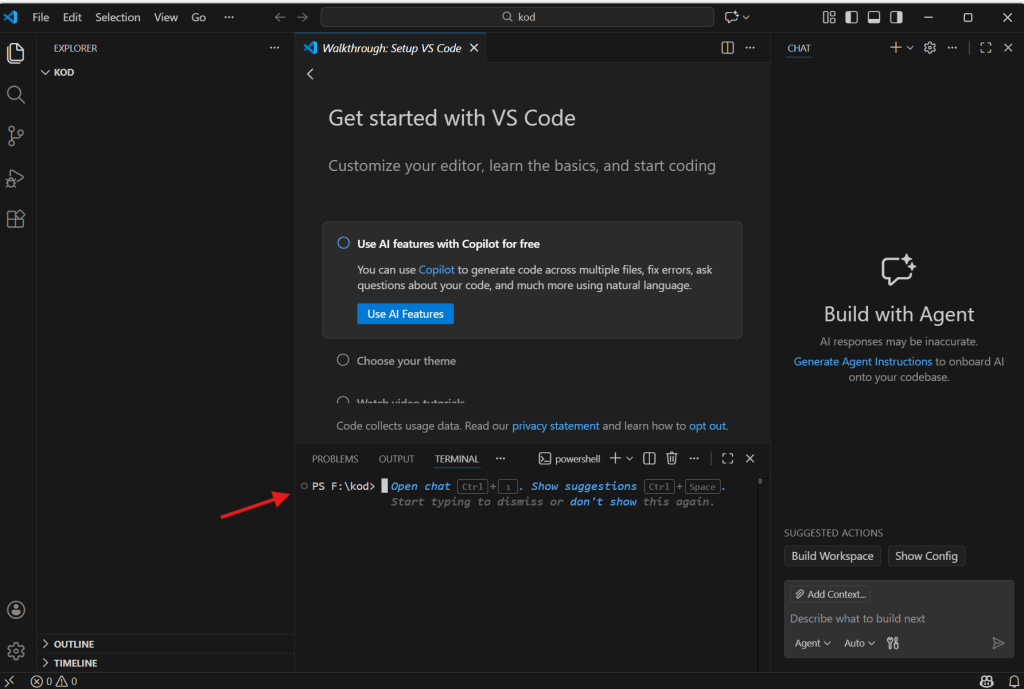
Ctrl + ” tuş kombinasyonuyla VS Code terminalini açın. ” karakteri ESC tuşunun hemen altındaki tuşla yazılıyor.
Bu adımdan sonra her kurulumda karşılaştığım bir hatanın çözümünü anlatacağım.
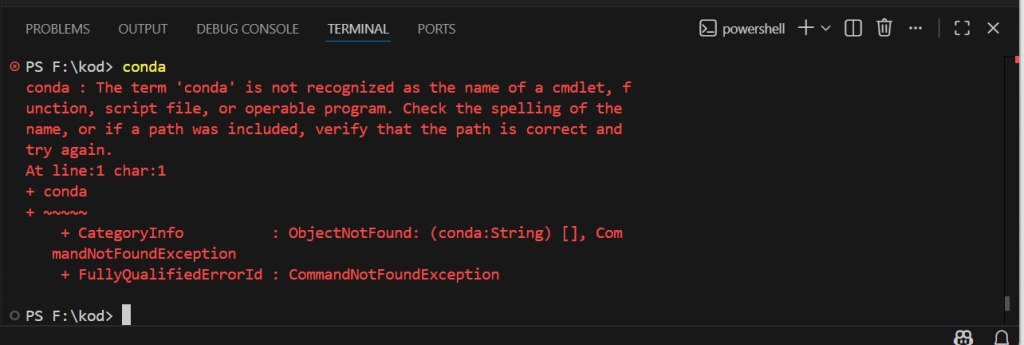
Normal şartlar altında conda komutuna terminalin tepki vermesi gerekirken hata veriyor. Bunu şu şekilde çözeceğiz.
Terminale bunu yazın notepad $PROFILE
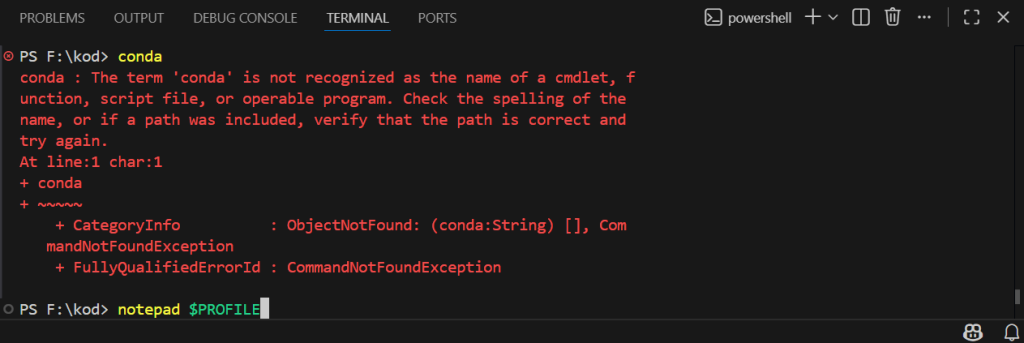
Karşınıza bir not defteri çıkacak. Aşağıdaki kodu ekleyin. Fark edebileceğiniz gibi C:\miniconda3 yoluyla başlıyor. Bu yol anaconda/minicondayı kurarken belirlediğiniz yoldur.
. "C:\miniconda3\shell\condabin\conda-hook.ps1"
Bu dosyayı kaydettikten sonra terminali ilgili kısımdan kapatın ve Ctrl + ” tuş kombinasyonu ile tekrar açın. Ardından conda komutunu tekrar verin.
EĞER conda komutu yine hata verirse powershell’i yönetici olarak çalıştırın ve bu komutu girin.
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
Y harfini girerek onaylayın.
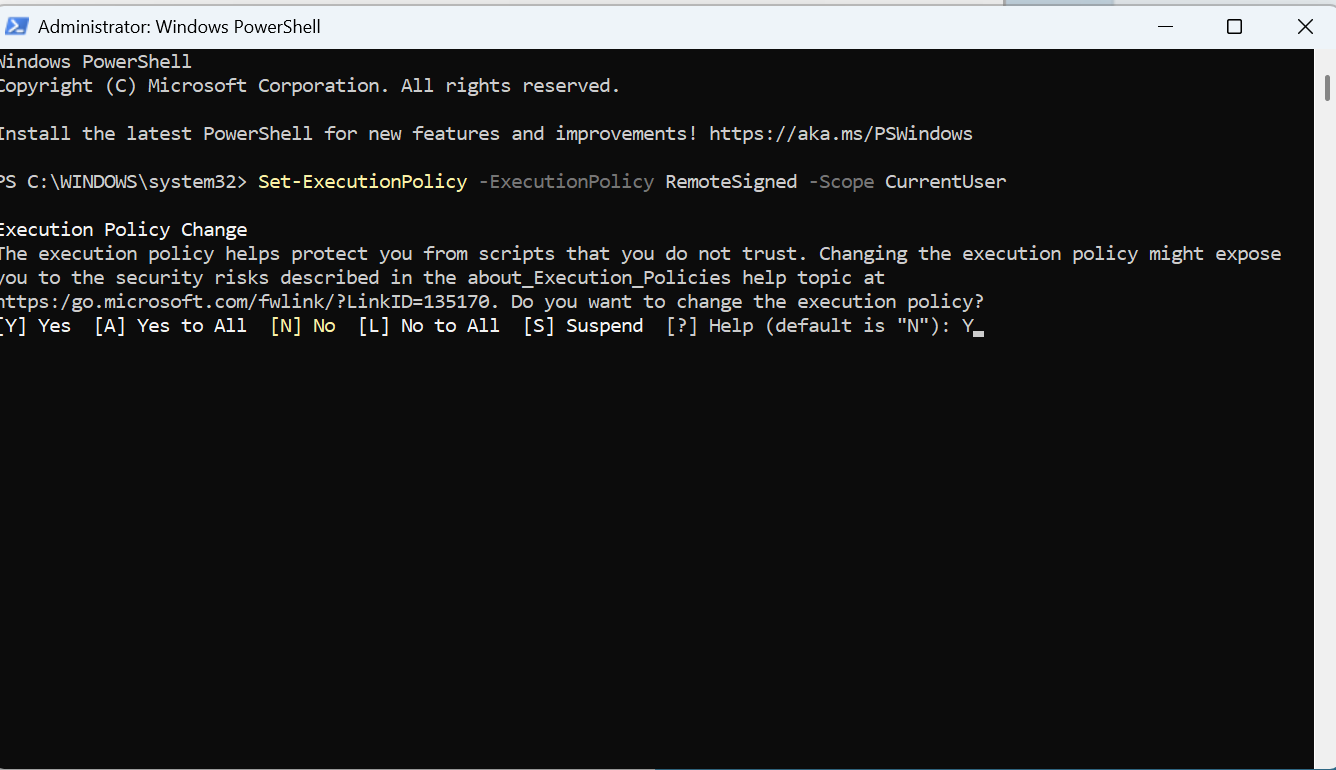
Bu işlemlerden sonra conda komutunu verdiğinizde böyle bir ekranın çıkması gerekiyor. Terminali kapatıp açmayı unutmayın.
Bundan sonra bir hatayla daha karşılaşacaksınız. Terminale şu kodu girin.
conda create -n yolo_od python=3.10 -y
Bu kodla conda ortamını oluşturuyor. Adını yolo_od olarak belirliyor, python=3.10 sürümünü yüklüyoruz. -y ifadesi sorulan sorulara otomatik yes cevabını veriyor.
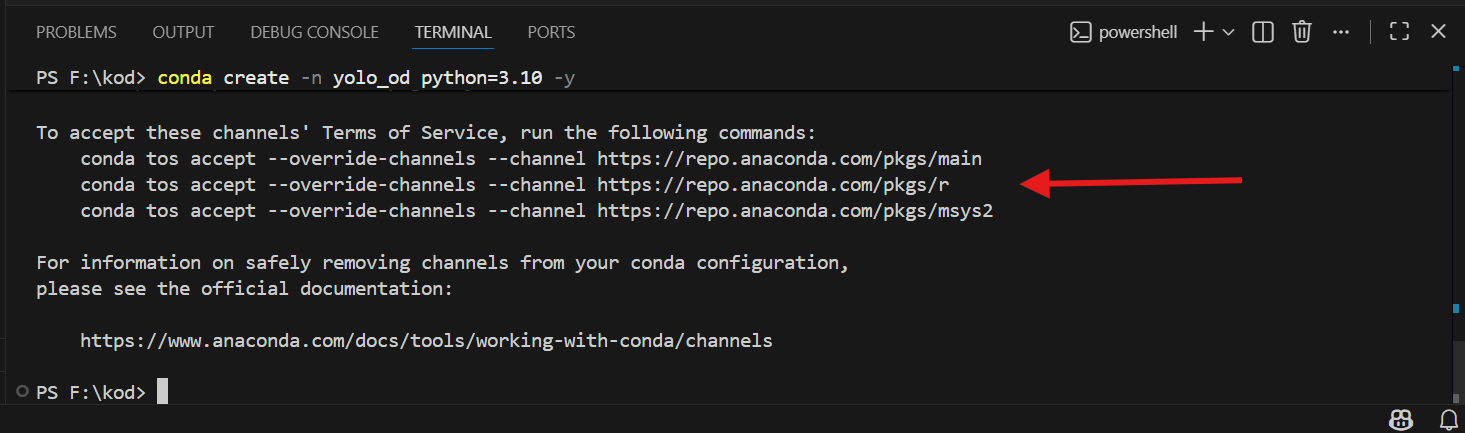
Sizden Terms Of Service’i kabul etmenizi istiyor. Okla gösterdiğim üç tane kodu arka arkaya girin.

Sonuç bu şekilde olacak. Ardından tekrar yandaki kodu kullanarak conda ortamını kurabiliriz.
conda create -n yolo_od python=3.10 -y
Ardından yandaki kodla ortamı aktifleştirin. Ortam adınız terminalde parantez içerisinde belirecek.
conda activate yolo_od

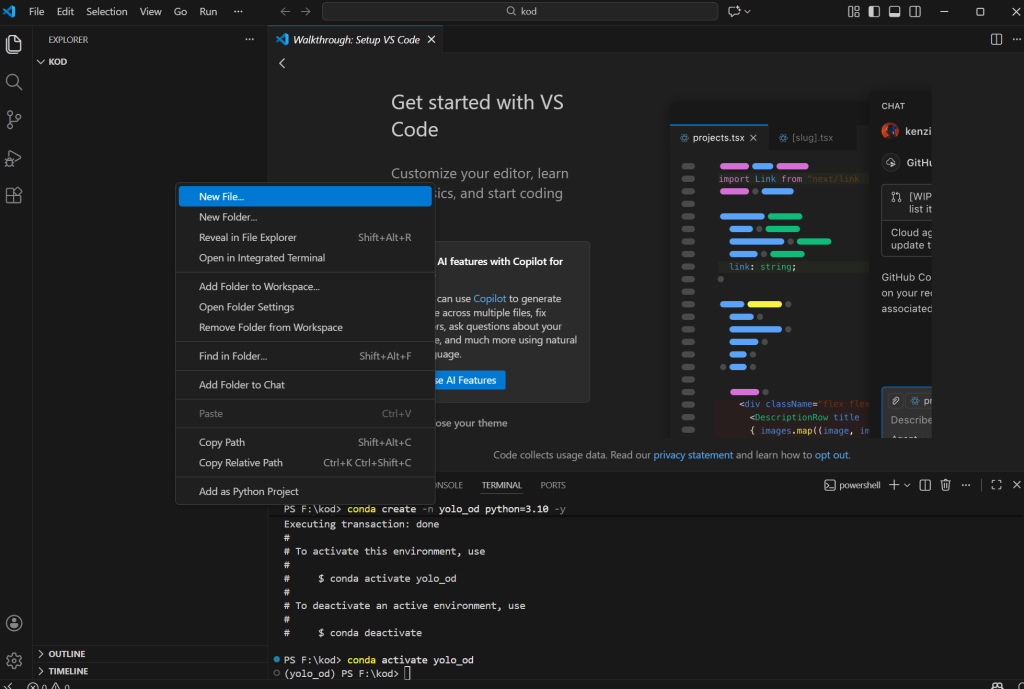
Bu adımdan sonra soldaki boş alana sağ tıklayın ve “New File” seçeneğiyle bir dosya oluşturun. İsmini test.py olarak belirleyin.
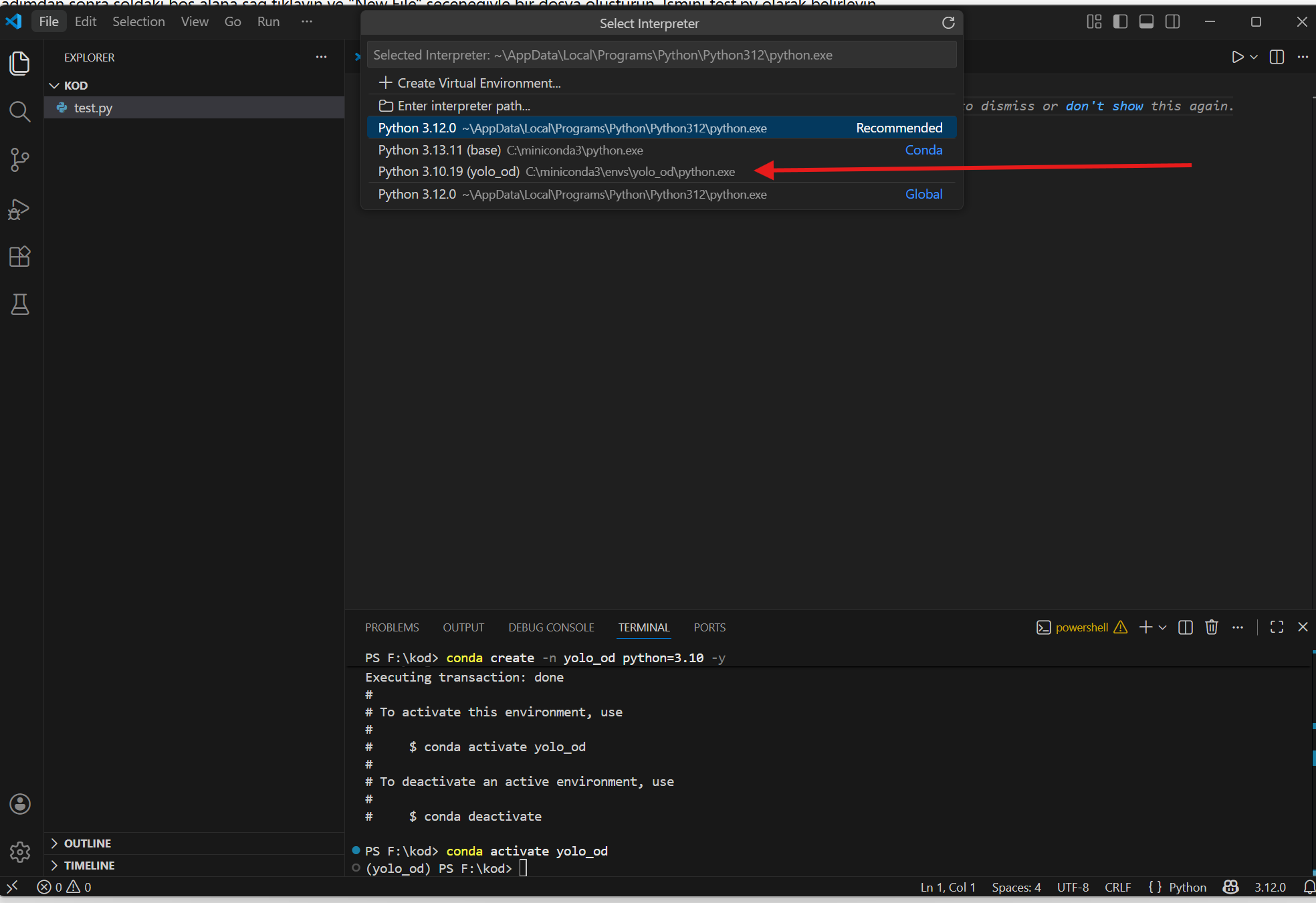
Okla gösterdiğim kısım sizde Select Interpreter olarak gözükebilir. Tıklayın. Üst tarafta bir pencere açılacak. Buradan bizim oluşturduğumuz ortamı seçin. Artık kodlarımız bizim ortamımızda, bu ortama yükleyeceğimiz kütüphanelerle çalışacak.
Bu adımlardan sonra kurulum işlemleri bitti. Gerektiği yerde ilgili kütüphaneleri kurarak kuruluma devam edeceğiz. Sıradaki adım veri toplama işlemleri
Veri Setinin Hazırlanması
Veri toplama
Verileri toplama biçimi farklılar arz etmekte.
- Koşullar
- Veri sayısı
- Işık
- Açı
- Pürüz, kir, toz
- vb.
- Cihaz
- Fotoğraf mı video mu
Koşullar
Gerekli veri sayısı kullanılan modele, detaya, çözünürlüğe vb. birçok parametreye göre değişmekte. Sınıf sayısı da bu veri ihtiyacını farklılaştıran etmenlerden birisi. Örnek vermek gerekirse 5 nesne varsa her nesne için 200 fotoğraf ile başlanabilir ANCAK bunlar seri üretim fotoğraflar değil ışık, açı, arka plan gibi koşullar değiştirilerek çeşitlendirilmiş veriler olmalı. Veri konusunda ayrı bir yazı yazmayı/videoda bu konuya ayrıntılı bir şekilde girmeyi, yarı manuel etiketleme gibi yöntemlerden bahsetmeyi düşünüyorum. Veri modelin başarısını etkileyen birinci faktör. Bu yüzden buraya azami dikkat etmeniz gerekiyor.
Nasıl veri toplayabilirsiniz?
Cihaz: Webcam, telefon vb. kameralar
Yöntem: Fotoğraf veya video
Ben size video yöntemini öneriyorum. Tek tek fotoğraf çekmekle uğraşmaktansa video çekip bu videoyu kodla parçalayarak veri setinin hazırlanması daha kolay olacaktır. Burada dikkat edilmesi gereken konu, veri kaydetme aralığı uzun tutularak veri setinin birbirine benzer görüntülerle şişirilmesini önlemek.
Webcam ile kare kaydetme kodu
Aşağıda verdiğim kod boşluk tuşuna bastığınızda koddaki saniyeye göre görüntü kaydediyor. Tekrar boşluk tuşuna basınca duraklatıyor. Q tuşuyla çıkıyor. Kodun işlevlerini ilgili satırlarda açıkladım. Bu satırları değiştirerek şartlara uyum sağlayabilirsiniz. Bu kodu çalıştırmadan önce conda ortamı aktifken terminalde şu kodu çalıştırmanız gerekiyor. conda ortamı aktif değilse önce conda kodunu girin.
Not: bu kodu yapay zekaya yazdırdım. Kodlama öğrenirken yapay zekadan yararlanabilirsiniz ancak iş kopyala yapıştırda kalırsa ileriye gidemezsiniz. Örnek vermek gerekirse yapay zeka size Pytorch’da transfer öğrenmesi kodu verebilir, hatta mimariyi değiştirebilir bunda bir sakınca da yok.
Ancak “nn.MaxPool2d(kernel_size=2, stride=2)” kodunun altında yatan matematiği bilmeniz gerekir. Şanslıyız ki yapay zeka bunu da gayet güzel açıklamakta. Size kalan görev bol bol çalışmak, bol bol kurcalamak. Makine öğrenmesi ve derin öğrenme için matematik, istatistik, olasılık, lineer cebir temelinizin bir miktar olması gerekiyor.
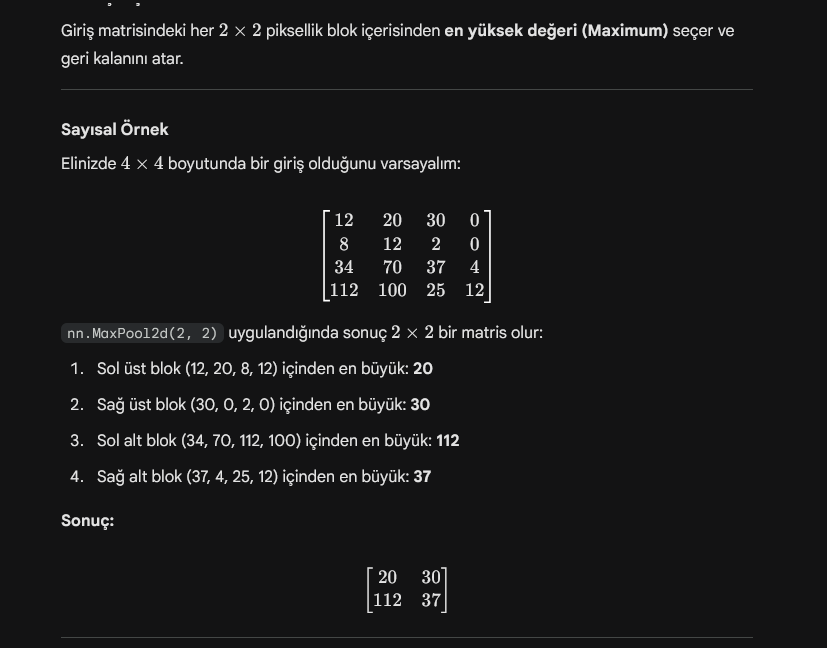
Konuya geri dönersek.
conda activate yolo_od pip install opencv-python Bu kod kamera işlemleri için gerekli görüntü işleme kütüphanesi opencv'yi yükler.
Aşağıdaki kodu webcam_capture.py adında bir dosya(ana klasör içinde, VS Code’da sol tarafta boş bir alana sağ tık – new file diyerek) oluşturup yapıştırın.
import cv2
import os
import time
# --- AYARLAR ---
folder_name = r"F:\kod\dataset\webcam" # görüntülerin nereye kaydedileceğini belirler.
save_interval = 0.5 # Kaç saniyede bir kare kaydedeceğini belirler.
camera_index = 0 # laptop kullanıyorsanız ve harici webcam yerine kendi kamerasını açıyorsa 1 yapın.
img_prefix = "train_data_" # Dosya adı ön eki
# folder_name değişkenindeki yol eğer yoksa klasörü otomatik oluşturur.
if not os.path.exists(folder_name):
os.makedirs(folder_name)
print(f"✅ Klasör oluşturuldu: {folder_name}")
# Kamera Bağlantısı
cap = cv2.VideoCapture(camera_index)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1280)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)
recording = False # Başlangıçta kayıt kapalı
count = 0
last_saved_time = time.time()
print(f"📂 Kayıt Yolu: {folder_name}")
print(f"⏱️ Aralık : {save_interval} saniye")
print("⌨️ BAŞLAT / DURAKLAT: [SPACE] (Boşluk)")
print("⌨️ PROGRAMI KAPAT : [Q]")
print("-------------------------------\n")
while True:
ret, frame = cap.read()
if not ret:
print("❌ Kameradan görüntü alınamadı!")
break
# Ekranda gösterilecek kopya (Yazılar orijinal kareye işlenmesin diye)
display_frame = frame.copy()
# Durum Bilgisi Yazdır (Yeşil: Kayıtta, Kırmızı: Duraklatıldı)
status_text = "KAYITTA" if recording else "DURAKLATILDI"
color = (0, 255, 0) if recording else (0, 0, 255)
cv2.putText(display_frame, f"Durum: {status_text}", (20, 40),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, color, 2)
cv2.putText(display_frame, f"Kare Sayisi: {count}", (20, 80),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (255, 255, 255), 2)
cv2.imshow("YOLO Veri Toplama Arayuzu", display_frame)
# Tuş Kontrolü
key = cv2.waitKey(1) & 0xFF
# SPACE: Kaydı Aç/Kapat
if key == ord(' '):
recording = not recording
state = "baslatildi" if recording else "duraklatildi"
print(f"ℹ️ Kayıt {state}.")
# Q: Çıkış
elif key == ord('q'):
print("🏁 İşlem sonlandırılıyor...")
break
# Kayıt Mantığı
if recording:
current_time = time.time()
if current_time - last_saved_time >= save_interval:
# Unix Timestamp ile Benzersiz İsimlendirme
timestamp = int(current_time * 1000)
file_name = f"{img_prefix}{timestamp}.jpg"
file_path = os.path.join(folder_name, file_name)
cv2.imwrite(file_path, frame) # Orijinal (yazısız) kareyi kaydet
count += 1
last_saved_time = current_time
if count % 10 == 0:
print(f"📸 {count} kare kaydedildi...")
# Kaynakları serbest bırak
cap.release()
cv2.destroyAllWindows()
print(f"\n✅ Bitti! Toplam {count} adet fotoğraf '{folder_name}' klasörüne kaydedildi.")
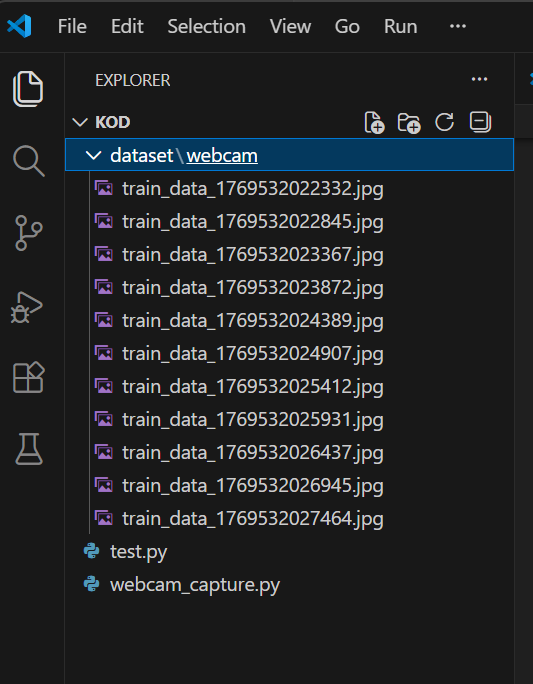
Kodu gösterdiğim kısımdan çalıştırın. Kamera ile görüntüleri kaydedin.
Verileriniz bu şekilde dataset\webcam klasöründe belirecek.
Telefonla veri toplama
Bu kısım daha sonra eklenecek, veri toplama yöntemleri kısmında daha detaylı işlenecektir.
Veri etiketleme
Veri etiketleme için XAnyLabeling uygulamasını kullanacağız. Yazının ileriki güncellemelerinde veya başka bir yazıda/videoda YOLO modeli eğiterek daha yarı otomatik veri etiketlemesi nasıl yapılır bunu anlatacağım.
X-AnyLabeling Github sayfası: https://github.com/CVHub520/X-AnyLabeling
Başlangıç sayfası: https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/en/get_started.md

conda deactivate komutu ile ortamı kapatın.
İleride GPU destekli otomatik etiketleme konusu atıldığında daha farklı bir kurulum yolu izlenecektir. Bu rehberde şimdilik cpu versiyonunun kurulumu ile yetinilmiştir.
Sırasıyla bu komutları çalıştırın.
conda create --name x-anylabeling-cpu python=3.10 -y conda activate x-anylabeling-cpu pip install x-anylabeling-cvhub[cpu] xanylabeling
Uygulama açıldıktan sonra aşağıdaki adımları izleyin ve görüntülerin olduğu klasörü seçin
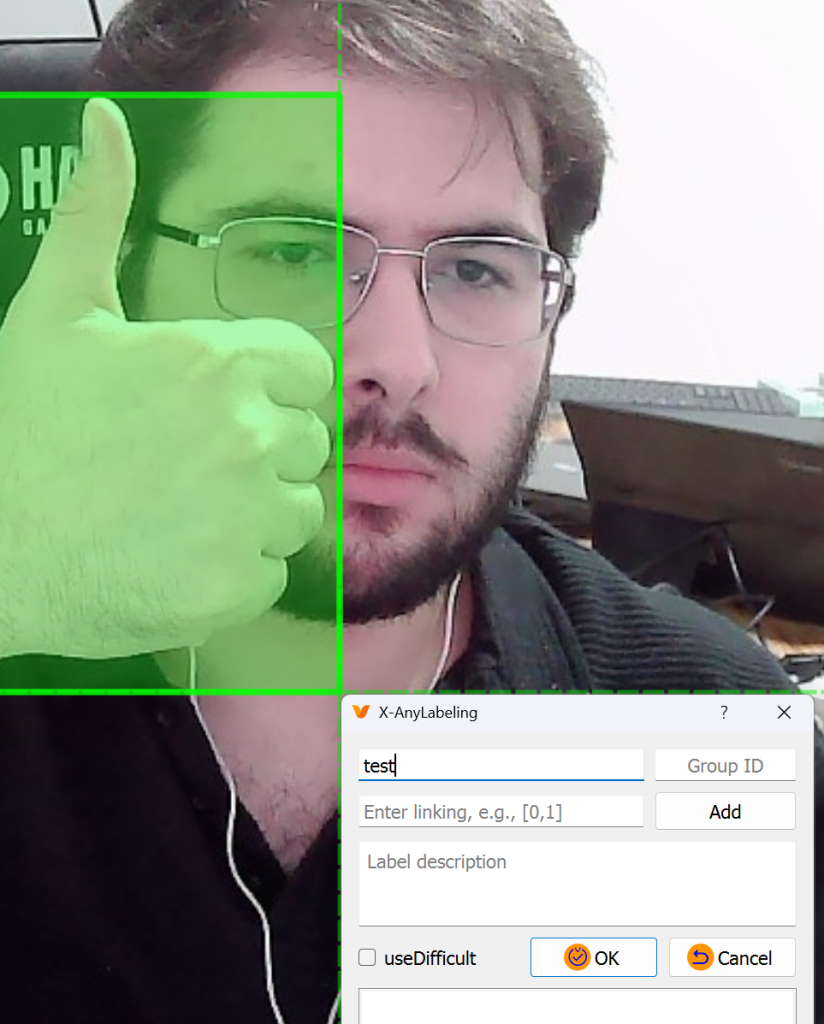
R tuşu ile rectangle çizin ve test yazdığım kısma nesnenin adını yazın. D tuşu ile bir sonraki görüntüye geçin.
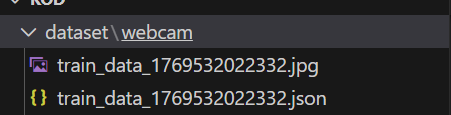
Etiketlemeleri bitirdikten sonra elinizde şöyle görüntüler ve JSON dosyaları olan bir klasör olacak.
Ana klasörde train_val_ayir.py adında bir dosya oluşturun ve aşağıdaki kodu yapıştırın. İlgili kısımları düzenlemeyi unutmayın. Bu kod JSON dosyalarını .txt formatına çeviriyor 80 – 20 oranında dosyaları train – val şeklinde yoloya uygun bir klasörde ayırıyor.
Kodu çalıştırmadan önce conda activate yolo_od komutunu verin.
import json
import os
import random
import shutil
from pathlib import Path
# --- AYARLAR ---
# JSON ve fotoğrafların olduğu ana klasör
source_dir = r"F:\kod\fotolar" #ben daha önceden etiketlediğim veri setini kullanacağım. Siz hangi klasörde topladıysanız onları kullanın.
# Veri setinin oluşturulacağı hedef klasör
output_dir = r"F:\kod\dataset" #dataset klasörü sizde oluştu varsayıyorum. Bu şekilde bırakın.
# Sınıf isimlerini JSON'daki sıraya veya kendi istediğin sıraya göre tanımla
classes = ["kup", "piramit", "kure", "silindir", "dikdortgen"] #sıra önem arz edecek. Nesneleri isteğinize göre sıralayın ama BİR DAHA DOKUNMAYIN.
# Bölünme oranı
train_ratio = 0.8
def convert_to_yolo(points, img_w, img_h):
"""X-AnyLabeling noktalarını YOLO formatına (x_center, y_center, w, h) çevirir."""
xs = [p[0] for p in points]
ys = [p[1] for p in points]
xmin, xmax = min(xs), max(xs)
ymin, ymax = min(ys), max(ys)
# YOLO normalizasyon hesaplamaları
x_center = (xmin + xmax) / 2.0 / img_w
y_center = (ymin + ymax) / 2.0 / img_h
w = (xmax - xmin) / img_w
h = (ymax - ymin) / img_h
return x_center, y_center, w, h
# 1. Klasör Yapısını Oluştur
for split in ['train', 'val']:
os.makedirs(os.path.join(output_dir, 'images', split), exist_ok=True)
os.makedirs(os.path.join(output_dir, 'labels', split), exist_ok=True)
# 2. Dosyaları Listele (Sadece JSON'ları baz alıyoruz)
json_files = [f for f in os.listdir(source_dir) if f.endswith('.json')]
random.shuffle(json_files)
split_idx = int(len(json_files) * train_ratio)
train_files = json_files[:split_idx]
val_files = json_files[split_idx:]
def process_files(file_list, split_type):
for json_name in file_list:
json_path = os.path.join(source_dir, json_name)
with open(json_path, 'r', encoding='utf-8') as f:
data = json.load(f)
img_w = data['imageWidth']
img_h = data['imageHeight']
img_name = data['imagePath']
# Txt dosya adını hazırla
txt_name = os.path.splitext(json_name)[0] + ".txt"
txt_path = os.path.join(output_dir, 'labels', split_type, txt_name)
yolo_lines = []
for shape in data['shapes']:
label = shape['label']
if label not in classes:
continue
class_id = classes.index(label)
points = shape['points']
# Koordinat dönüşümü
bb = convert_to_yolo(points, img_w, img_h)
yolo_lines.append(f"{class_id} {' '.join([f'{x:.6f}' for x in bb])}")
# 3. Yazma ve Kopyalama İşlemleri
# TXT Dosyasını Yaz
with open(txt_path, 'w') as f:
f.write('\n'.join(yolo_lines))
# Fotoğrafı Kopyala
src_img_path = os.path.join(source_dir, img_name)
dst_img_path = os.path.join(output_dir, 'images', split_type, img_name)
if os.path.exists(src_img_path):
shutil.copy(src_img_path, dst_img_path)
else:
print(f"⚠️ Uyarı: {img_name} bulunamadı!")
# İşlemi Başlat
print("🚀 Veri seti dönüştürme ve bölme işlemi başladı...")
process_files(train_files, 'train')
process_files(val_files, 'val')
print(f"✅ İşlem tamamlandı! Veri seti '{output_dir}' konumunda hazır.")
print(f"📊 Özet: {len(train_files)} train, {len(val_files)} val dosyası oluşturuldu.")

Sonuç bu şekilde. Train – Val ayrımı yapıldı.
Bir sonraki adım data.yaml dosyasını oluşturmak.
“New File” seçeneği ile dataset klasörü içinde data.yaml adında bir dosya oluşturun. Bu klasörün bulunduğu yol(İÇERİKTEN BAHSETMİYORUM DOSYANIN BİZATİHİ BULUNDUĞU KONUM) F:\kod\dataset\data.yaml bu şekilde olmalı
# --- DATASET PATHS --- path: F:/kod/dataset train: images/train val: images/val # --- CLASS CONFIGURATION --- nc: 5 # SIRA KRİTİKTİR: classes = ["kup", "piramit", "kure", "silindir", "dikdortgen"] names: 0: kup 1: piramit 2: kure 3: silindir 4: dikdortgen
Bu yaml dosyasını oluşturduktan sonra sıra son kütüphaneleri kurmaya geldi.
pip install ultralytics
Bu koddan sonra ana klasörde pytorch_test.py adında bir python dosyası oluşturun. Bu kodu yapıştırın ve çalıştırın.
import torch
import sys
def check_pytorch_setup():
print("-" * 30)
print("PYTORCH DONANIM DOĞRULAMA")
print("-" * 30)
# 1. Python ve PyTorch Versiyon Bilgisi
print(f"Python Sürümü: {sys.version}")
print(f"PyTorch Sürümü: {torch.__version__}")
# 2. CUDA (GPU) Erişilebilirliği
cuda_available = torch.cuda.is_available()
print(f"CUDA Erişilebilir mi?: {cuda_available}")
if cuda_available:
# 3. GPU Bilgileri
device_id = torch.cuda.current_device()
gpu_name = torch.cuda.get_device_name(device_id)
print(f"Aktif GPU Cihazı: {gpu_name}")
print(f"CUDA Versiyonu: {torch.version.cuda}")
# 4. Gerçek Dünya Testi (Tensör İşlemi)
# GPU üzerinde rastgele bir matris oluşturup işlem yapıyoruz
try:
print("\n[TEST] GPU üzerinde tensör oluşturuluyor...")
x = torch.rand(5, 3).to("cuda")
print("GPU Tensörü:")
print(x)
# Basit bir matris çarpımı ile GPU çekirdeklerini tetikle
y = torch.ones_like(x).to("cuda")
z = x + y
print("\n[BAŞARILI] GPU üzerinde matematiksel işlem gerçekleştirildi.")
except Exception as e:
print(f"\n[HATA] GPU işlemi sırasında sorun oluştu: {e}")
else:
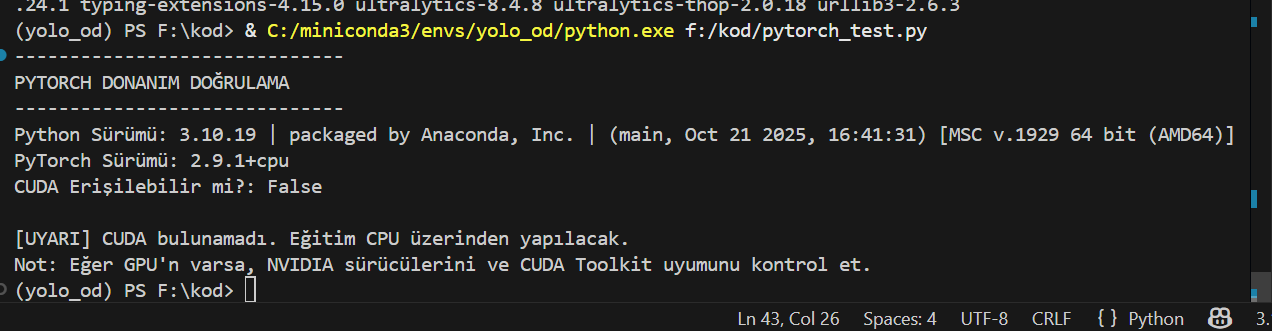
print("\n[UYARI] CUDA bulunamadı. Eğitim CPU üzerinden yapılacak.")
print("Not: Eğer GPU'n varsa, NVIDIA sürücülerini ve CUDA Toolkit uyumunu kontrol et.")
if __name__ == "__main__":
check_pytorch_setup()
Bu kodu çalıştırdığınızda GPU hatası vermezse ne ala. GPU ile eğitim yapabilirsiniz. Eğer GPU hatası verirse ardından ilgili Pytorch sürümünü kurmanız gerekiyor.
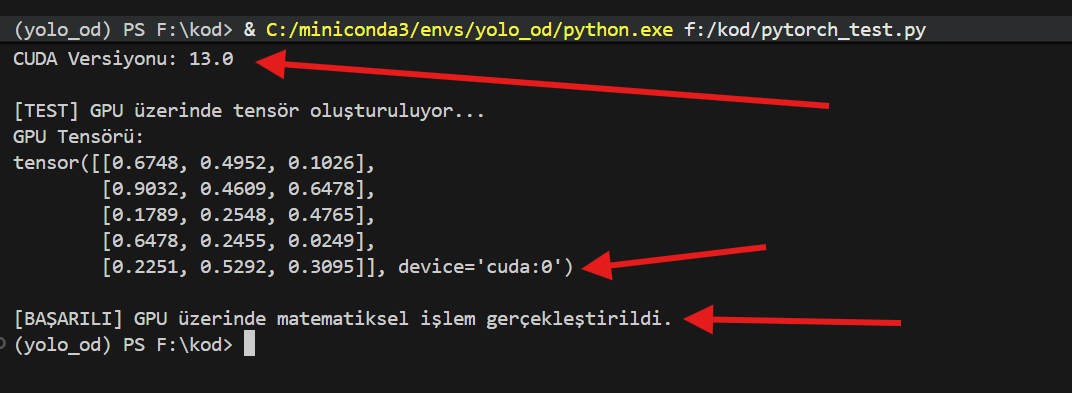
Ben RTX 5070 Ti kullandığım için Cuda 13 versiyonunu kuracağım. Bu sürümü kurduğumda bağımlılık hatası veriyormuş gibi gözükse de pytorch_test.py kodu GPU’nun çalıştığını doğruluyor ve az sonra vereceğim train.py kodu çalıştığında eğitimi GPU yapıyor.
pip uninstall torch torchvision #yes no sorarsa(soracak) y ile onaylayın. pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu130

pytorch_test.py kodunu tekrar çalıştırın.
ana klasörde train.py adında bir python dosyası oluşturun ve verdiğim kodları yapıştırın. Ardından çalıştırın.
from ultralytics import YOLO
# Windows multiprocessing (çoklu işlem) hatasını önlemek için bu blok zorunludur.
if __name__ == "__main__":
# 1. MODEL SEÇİMİ
# 'yolov8n.pt' Nano modeldir. 3.2M parametre ile hem hızlı eğitilir
# hem de RTX 5070 Ti gibi güçlü kartlarda 200+ FPS değerlerine ulaşabilir.
model = YOLO("yolov8n.pt")
# 2. EĞİTİM BAŞLATMA
model.train(
# --- TEMEL YAPILANDIRMA ---
data=r"F:\kod\dataset\data.yaml", # Sınıf isimleri ve klasör yollarının olduğu dosya.
epochs=100, # Veri setinin üzerinden kaç tur geçileceği.
imgsz=640, # Görsel boyutu. 640x640 YOLOv8 için altın standarttır.
device=0, # 0: İlk GPU (RTX 5070 Ti). CPU için 'cpu' yazılır.
# --- PERFORMANS VE DONANIM ---
batch=64, # VRAM kapasitesine göre bir seferde işlenen resim sayısı.
# Düşük olması eğitimi yavaşlatır, yüksek olması VRAM'i doldurabilir.
workers=4, # Veriyi diskten okuyup GPU'ya hazırlayan CPU çekirdek sayısı.
# Windows'ta stabilite için 4-8 arası önerilir.
# --- EĞİTİM STRATEJİSİ (HİPERPARAMETRELER) ---
patience=20, # Sabır: Eğer model 20 tur boyunca iyileşmezse eğitimi otomatik durdurur.
optimizer='AdamW', # Hataları düzelten matematik motoru. AdamW, Blackwell mimarisinde hızlı sonuç verir.
lr0=0.01, # Başlangıç Öğrenme Oranı: Yapay zekanın "adım büyüklüğü".
lrf=0.01, # Final Öğrenme Oranı Çarpanı: Eğitim sonunda adımların ne kadar küçüleceği.
momentum=0.937, # Gradyan hızını koruma katsayısı. Modelin "çukur" (local minima) noktalarına takılmasını önler.
weight_decay=0.0005, # Aşırı öğrenmeyi (ezberlemeyi) önlemek için ağırlıkları cezalandıran katsayı.
# --- VERİ ARTIRMA (AUGMENTATION) ---
# Elimizdeki kısıtlı veriyi "yapay" yollarla çoğaltan mühendislik hileleri:
mosaic=1.0, # 4 resmi kesip birleştirerek tek resim yapar. Karmaşık sahneleri öğretir.
degrees=10.0, # Resimleri ±10 derece döndürür. Farklı açılardan tanıma sağlar.
translate=0.1, # Resimleri %10 kaydırır. Nesne merkezde değilse de tanınmasını sağlar.
scale=0.5, # Nesneyi %50 büyütüp küçültür. Mesafe (yakın/uzak) algısı kazandırır.
fliplr=0.5, # Resmi yatayda %50 ihtimalle aynalar (simetri eğitimi).
# --- KAYIT VE ANALİZ ---
project="yolo_od_v1", # Projenin ana klasör adı.
name="train_v1", # Bu spesifik denemenin adı.
plots=True # Eğitim bittiğinde Loss ve mAP grafiklerini görselleştirir.
)
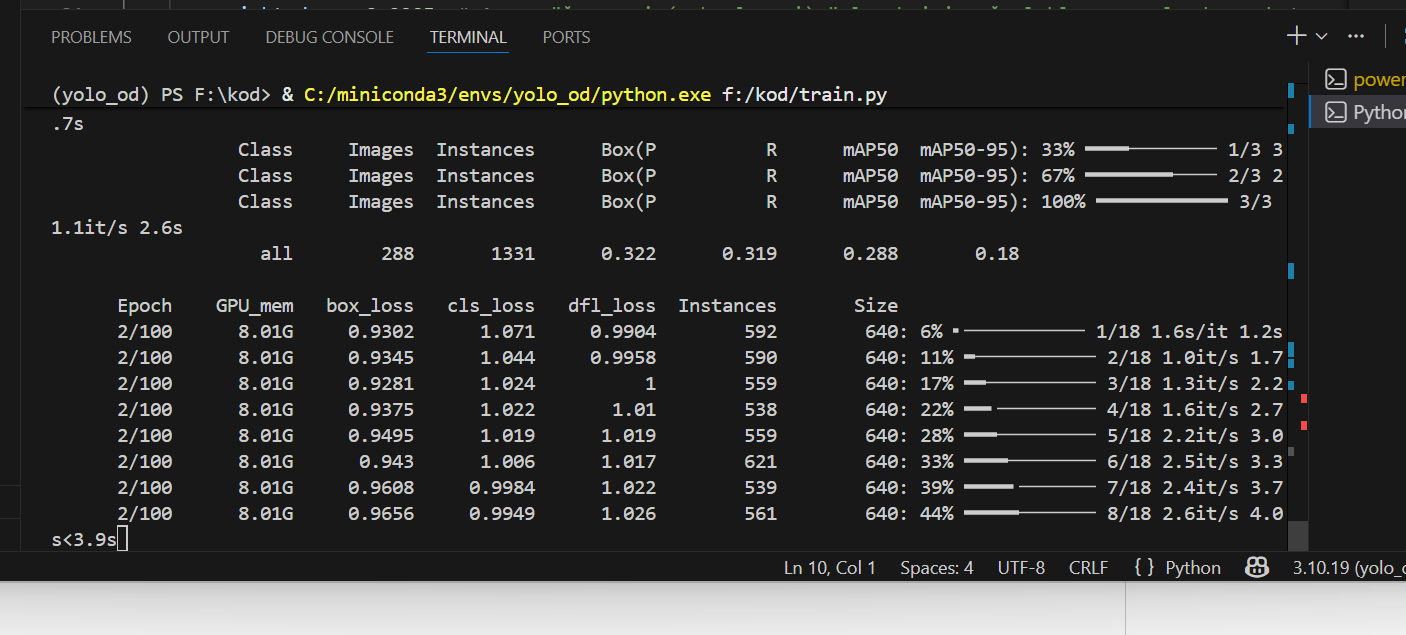
Eğitim başladı. patience = 20 satırı ile eğitim kayda değer bir ilerleme yaşamadığında eğitimi durduracak.
yolo_webcam_inference.py adında bir dosya oluşturun ve aşağıdaki kodu yapıştırın.
model_path değişkeni eğitilmiş en son modele ayarlanacak
import cv2
from ultralytics import YOLO
# 1. Eğittiğin Modeli Yükle
# 'best.pt' dosyan hangi klasördeyse onun tam yolunu belirt
model_path = r"F:\kod\runs\detect\yolo_od_v1\train_v13\weights\best.pt" #eğitilmiş modelin konumu
model = YOLO(model_path)
# 2. Kamerayı Başlat
cap = cv2.VideoCapture(0) # Harici kamera kullanıyorsan 1 yapabilirsin
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1280)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)
print("\n--- CANLI TEST BAŞLADI ---")
print("⌨️ ÇIKMAK İÇİN 'Q' TUŞUNA BASIN")
while True:
ret, frame = cap.read()
if not ret:
break
# 3. Model ile Tahmin Yap (Inference)
# stream=True parametresi Blackwell kartında daha akıcı performans sağlar
results = model(frame, stream=True, conf=0.7) # %70 güven eşiği
# 4. Sonuçları Ekrana Çiz
for r in results:
annotated_frame = r.plot() # Kutuları ve isimleri otomatik çizer
# 5. Görüntüyü Göster
cv2.imshow("YOLOv8 Canli Nesne Tespiti", annotated_frame)
# Q tuşuna basılırsa çık
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Kaynakları serbest bırak
cap.release()
cv2.destroyAllWindows()
Bununla birlikte rehberin sonuna geldik. Bu rehberi takip ederek kendi custom object detection modelinizi oluşturma yolunda yaşadığınız problemleri lütfen yorum satırında belirtin ve çözümüne birlikte bakalım.
Bir yanıt yazın